

Compliance en een Data Vault gaan hand in hand
Zoals aangegeven: de Data Vault (DV) maakt onderscheid tussen feiten (onbewerkt perspectief) en de waarheid (bewerkt perspectief). Dit kan handig zijn om geen enkele transactie of mutatie te verliezen. En is vanuit het oogpunt van compliance en wetgeving soms een must. Op alle velden hou je in de Data Vault consequent historie bij. Een ingenieuze constructie van hub-, link- en satelliettabellen zorgt voor flexibiliteit qua opslag.
Zoek de 4 verschillen tussen de derde normaalvorm en Data Vault
De modellering van een Data Vault verschilt enorm met die van reguliere datamodellering (3NF). Hieronder zie je de verschillen. Van vier tabellen (figuur 1) ga je naar negen tabellen (figuur 2). Een groot verschil is dus: meer tabellen. Welke verschillen zie jij nog meer? Laat een comment achter met je antwoord.
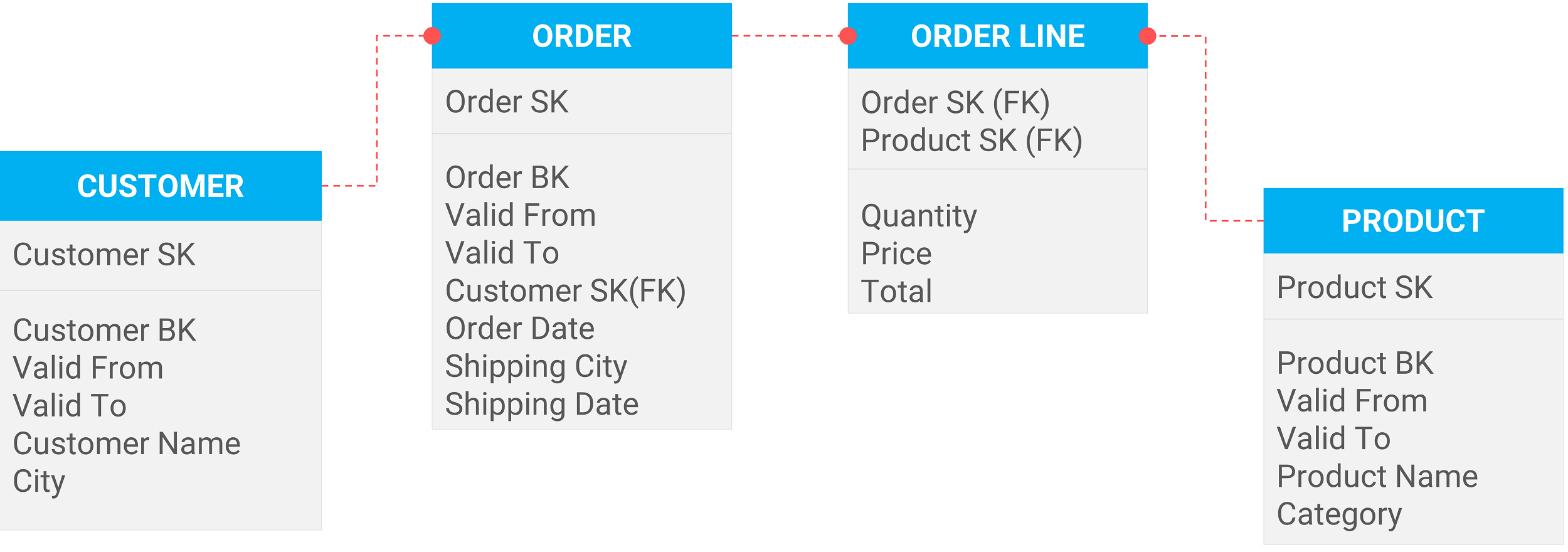
Figuur 1: orders van een bedrijf gemodelleerd volgens de derde normaalvorm (3NF)
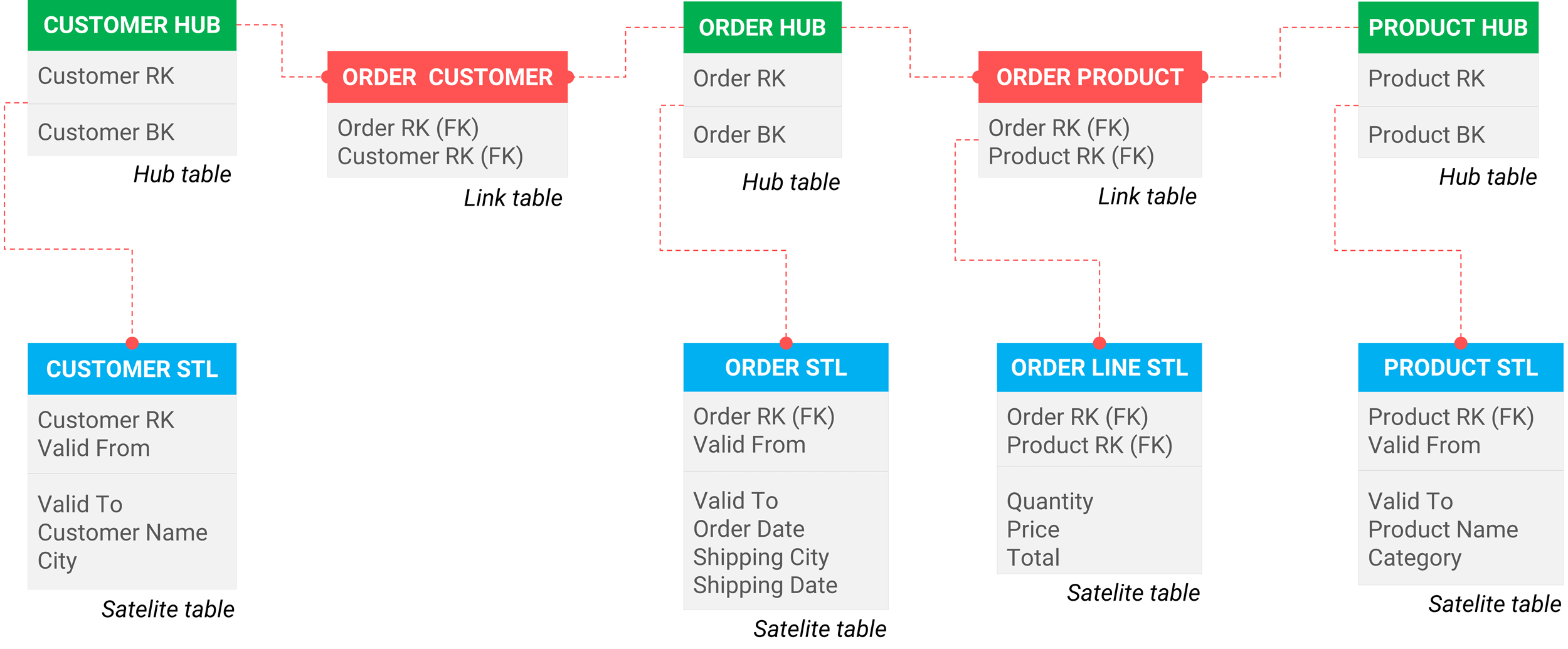
Figuur 2: orders van een bedrijf gemodelleerd volgens de Data Vault methodiek
Hoe geef je de transformatie van 3NF naar DV vorm?
- Elke mastertabel (referentietabel zoals customer) splits je in een hub- en een satelliettabel. De sleutels komen in de hubtabel. De beschrijvende velden komen in één of meerdere satelliettabellen.
- Hierdoor ontstaat de volgende flexibiliteit: aan de hub kun je eenvoudige meerdere satelliettabellen koppelen. Vandaar de naam ‘hub’. Zo koppel je makkelijk klantgegevens uit andere systemen of externe bronnen. Hierdoor blijven bestaande tabellen intact.
- Joins tussen twee mastertabellen geef je vorm met een linktabel. Hierdoor ontstaat flexibiliteit in het type relatie die gegevens met elkaar hebben.
- Elke transactietabel splits je in een link- en een satelliettabel. De sleutels komen in de linktabel. De transactiedetails komen in de satelliettabel.
Voorbeeld: stel dat orders opeens niet meer alleen door bedrijven maar ook door consumenten kunnen worden geplaatst? Dan volstaan een paar extra tabellen: Person Order Link (Person RK, Order RK), Person Hub (Person RK, ID (BK)) en Person Satellite (Person RK, first name, last name, etc.). Het huidige datamodel van de Data Vault blijft daarbij intact. Dat wil zeggen: het is niet nodig om bestaande tabellen aan te passen.
De 10 onweerlegbare feiten over de Data Vault
- Meer tabellen voor opslag: dataopslag in een Data Vault vergt meer tabellen. Tenminste twee keer zoveel tabellen zijn nodig.
- Meer joins voor ophalen data: er zijn meer complexe joins nodig om de juiste data te selecteren.
- Extra component: de Data Vault vormt een extra component in een volwassen DWH-architectuur. En dat betekent extra werk.
- Eindgebruikers mogen de Data Vault niet raadplegen. De reden? Die bevat mogelijk onjuiste of incomplete data.
- Drie modelleringstechnieken naast elkaar: in de complete DWH-architectuur komen met de Data Vault drie modelleringstechnieken voor: 3NF, Data Vault en Dimensioneel (sterschema, sneeuwvlok).
- Flexibiliteit in dataopslag: de Data Vault geeft op een aantal manieren flexibiliteit in dataopslag.
- Vrijheid: met name in de type relatie die entiteiten met elkaar kunnen hebben
- Extra flexibiliteit. Eenvoudig kunnen toevoegen van nieuwe bronnen en entiteiten. En hiervoor hoef je niet de bestaande structuur aan te passen.
- Meer dataopslag: ook foute of incomplete gegevens worden opgeslagen.
- Gesloten, veilige omgeving: voor eindgebruikers is het niet toegestaan om gegevens uit de Data Vault op te vragen. Deze kunnen immers onjuistheden bevatten. De Data Vault is dus secure zoals de naam al aangeeft.
Hoe geef je een Data Vault architectuur vorm?
Een Data Vault kan worden toegepast als Centraal Datawarehouse (CDW), maar ook als pre-CDW of Persistant Staging Area (PSA). Pas je de Data Vault als CDW toe dan is er geen sprake van een volwassen DWH-architectuur. Vanuit de Data Vault bouw je immers datamarts op en deze kennen een dimensionele structuur.
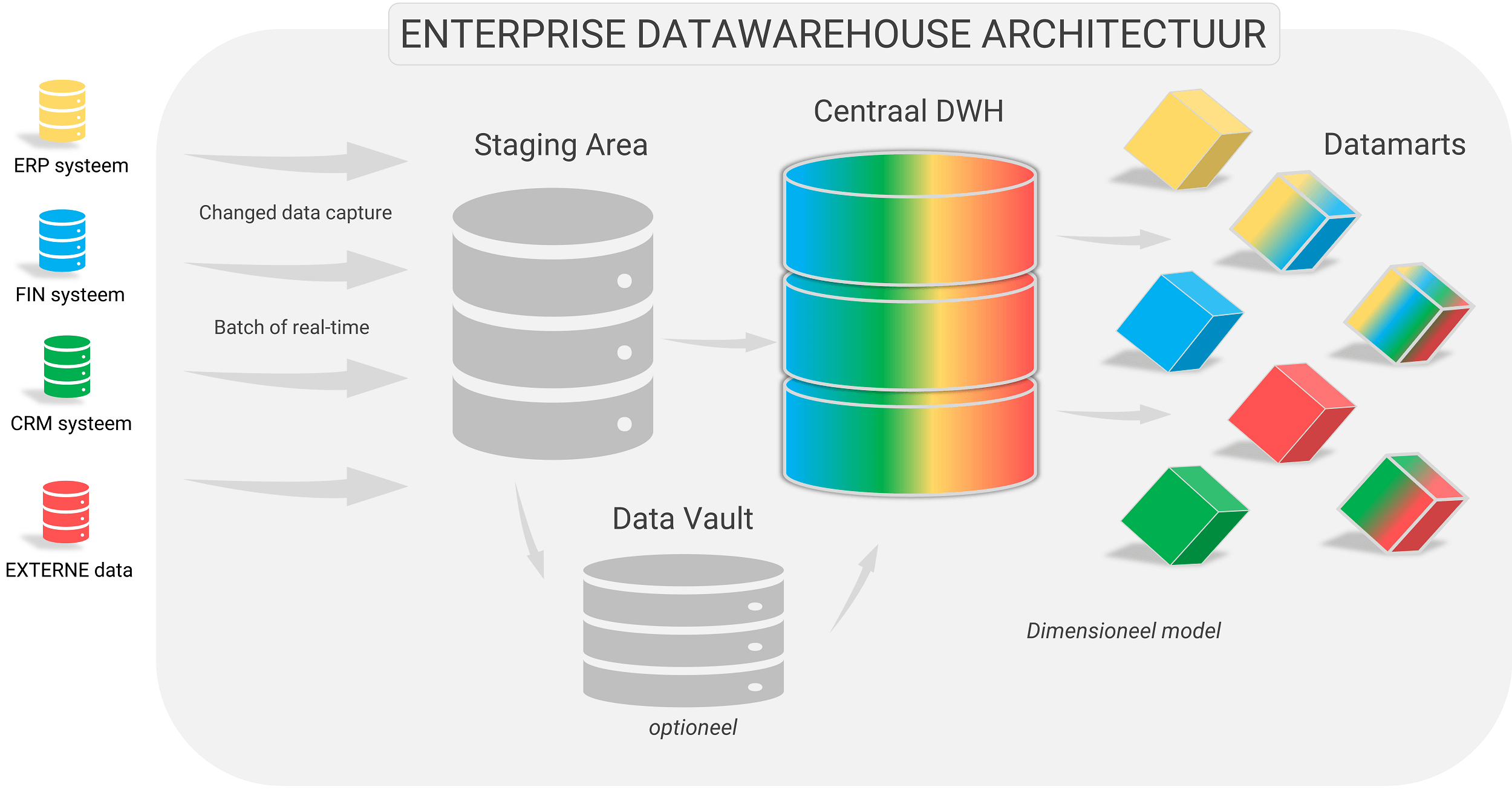
Figuur 3: De Data Vault route en de traditionele route van Business Analytics. Uit deze figuur blijkt dat het realiseren van een Data Vault extra werk met zich meebrengt en de architectuur complexer maakt.
Voor de detaildata moet je dan terug naar de Data Vault. Die kent een andere structuur en kent geen of andere transformaties. Bovendien kan die ook nog eens onjuiste data bevatten. Een drilldown op een Data Vault is dus ook gevaarlijk. Een Data Vault kan daarom nooit het CDW vervangen in een volwassen DWH-architectuur. Je wilt één versie van de waarheid en die kan dan niet meer worden afgedwongen. Of je kan dat alleen tegen heel veel meer kosten. Want, de datawarehousebus, die dat afdwingt, is er niet meer.
Voor één specifieke indicator zijn soms wel meerdere aggregatietabellen nodig. Elke datamart kan in theorie daarmee een geheel eigen waarheid creëren. Zo kan een Data Vault gemakkelijk ontaarden in een verzameling losse data-silootjes. Net als in het pré-datawarehousetijdperk.
Definitie: volwassen DWH-architectuur
In een volwassen DWH-architectuur worden een aantal functies uitgevoerd:
- je toetst de datakwaliteit
- je bouwt historie op
- je combineert data
- je dwingt consistentie af tussen gegevens
Voor het laatste denk je aan consistentie tussen aggregaties en de details maar ook over de aggregatietabellen heen.
In een Enterprise DWH architectuur kun je in principe voor 2 routes kiezen: de traditionele route (gewoon rechtdoor in onderstaande figuur) en de Data Vault route (eerst naar beneden en dan weer naar boven). Onderstaande figuur geeft dit weer.
De voordelen van de Data Vault
- Datamodel van de Data Vault staat los van het datamodel van de bronnen. Wijzigingen daarin hebben minder vaak impact op het datamodel van de Data Vault.
- Flexibiliteit in gegevensopslag en gemakkelijk uitbreidbaar. Eenvoudig bronnen kunnen toevoegen, zonder dat de huidige tabellen van de Data Vault qua structuur moeten wijzigen. Is die flexibiliteit ook op een andere wijze te realiseren? Een Data Vault is bij uitstek de manier om deze vorm van flexibiliteit te realiseren.
- Herlaadbaarheid: gegevens vanuit de Data Vault kun je altijd gebruiken om het CDW/datamarts te herladen, tot ver terug in de tijd. Ook in het geval bronsystemen inmiddels een andere structuur kennen.
- Compliance: altijd terug kunnen herleiden van de data, ongeacht structuurwijzigingen in bronsystemen.
- Snelheid van laden: wanneer er veel satelliettabellen zijn per hub, dan kun je deze parallel laden. Wanneer de hardware parallelle verwerking ondersteunt, gaat het laden van gegevens veel sneller.
De nadelen van de Data Vault
- Meer werk: de Data Vault is complexer om te maken. Daarnaast heb je nu een extra component die je ook moet onderhouden.
- Meer transformaties: in de Data Vault normaliseer je entiteiten verder dan de bron. Nadien moet er ’terug worden gewerkt’ naar een dimensioneel datamodel. Zie de afbeelding hierboven.
- Meer kennis nodig: met de Data Vault komt er een 3e modelleringstechniek bij. Medewerkers moeten die technieken stuk voor stuk beheersen.
- Geen integriteit: de gegevens in de Data Vault zijn niet integer en niet altijd juist.
BELANGRIJK: Wat gebeurt er na de Data Vault in het laadproces?
Het belangrijkste voordeel van de Data Vault is de flexibiliteit van dataopslag. In een volwassen DWH-architectuur heb je naast een Data Vault ook een CDW en mogelijk ook een of meerdere datamarts of kubussen nodig. Het is natuurlijk prachtig wanneer bij structuurwijzigingen in de bron de Data Vault niet per se hoeft te worden ‘opengebroken’. Maar dat geldt niet voor het CDW en de Datamarts, want deze zijn dimensioneel gemodelleerd (voorkeur) of 3NF. Om dit fenomeen te illustreren geven we twee voorbeelden.
Voorbeeld 1: van één sales manager naar meerdere sales managers
Een klant heeft niet langer slechts één sales manager maar kan vanaf vandaag meerdere sales managers hebben. De relatie tussen de entiteiten klant en sales manager gaat van 1:1 naar 1:n. Onder het mom van “laat de beste boven mogen komen drijven”.
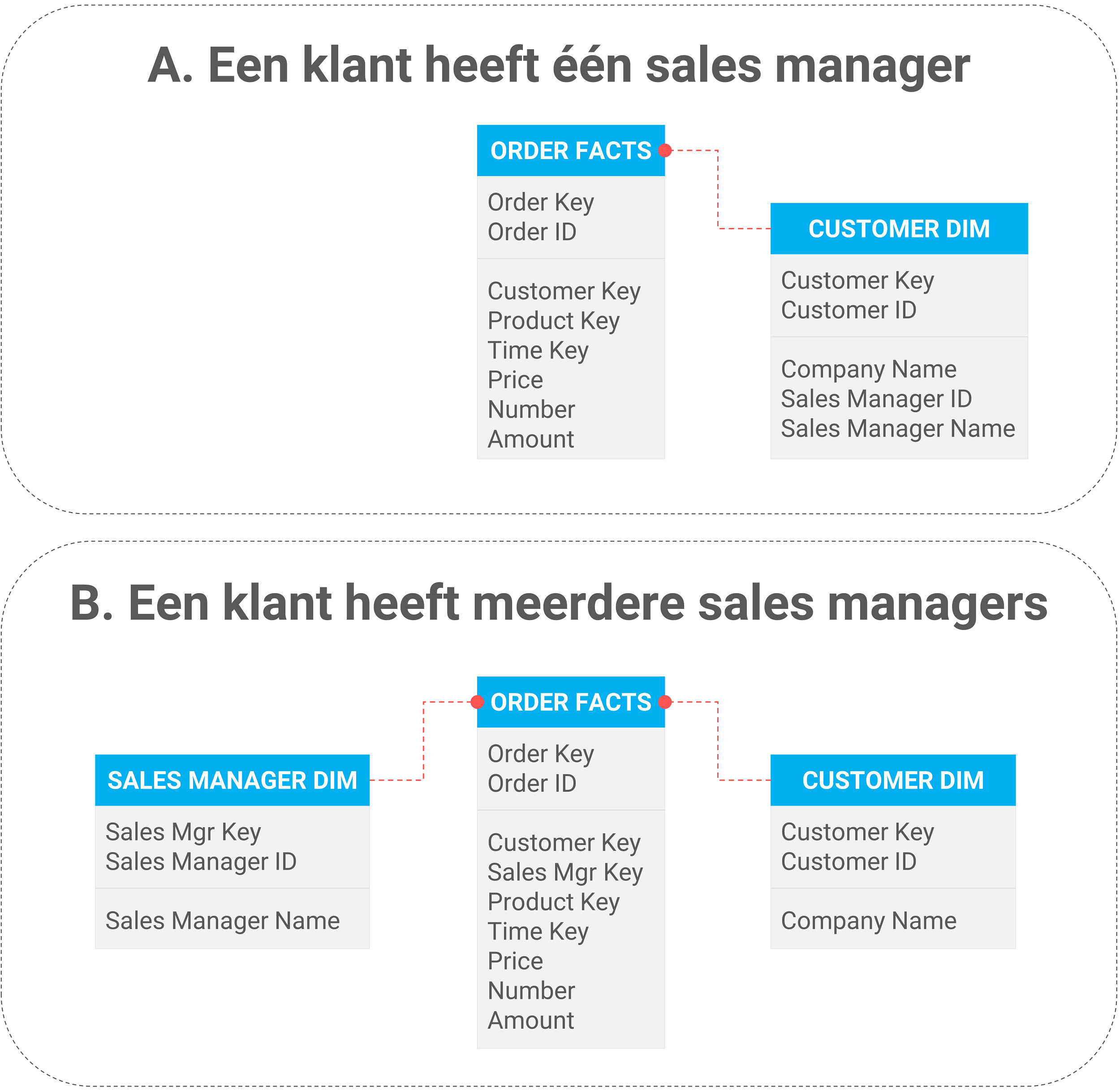
Figuur 4: datamodel van het DWH voordat de wijziging in de bron wordt gemaakt (sitatie A: een klant heeft 1 sales manager) en het datamodel nadat de bron is gewijzigd (situatie B: meerdere sales managers per klant)
Zoals zichtbaar wordt hierboven is er geen 1:1 relatie meer tussen klant en sales manager. Daarom koppel je de Sales Manager dimensie rechtstreeks aan de feittabel.
Voorbeeld 2: naast bedrijven ga je ook consumenten bedienen
Het bedrijf levert niet langer alleen aan bedrijven maar ook aan consumenten. Door de sterke toename van online verkopen vervalt ook de functie van sales manager. De hiervoor relevante attributen worden verwijderd uit de Customer dimensie tabel.
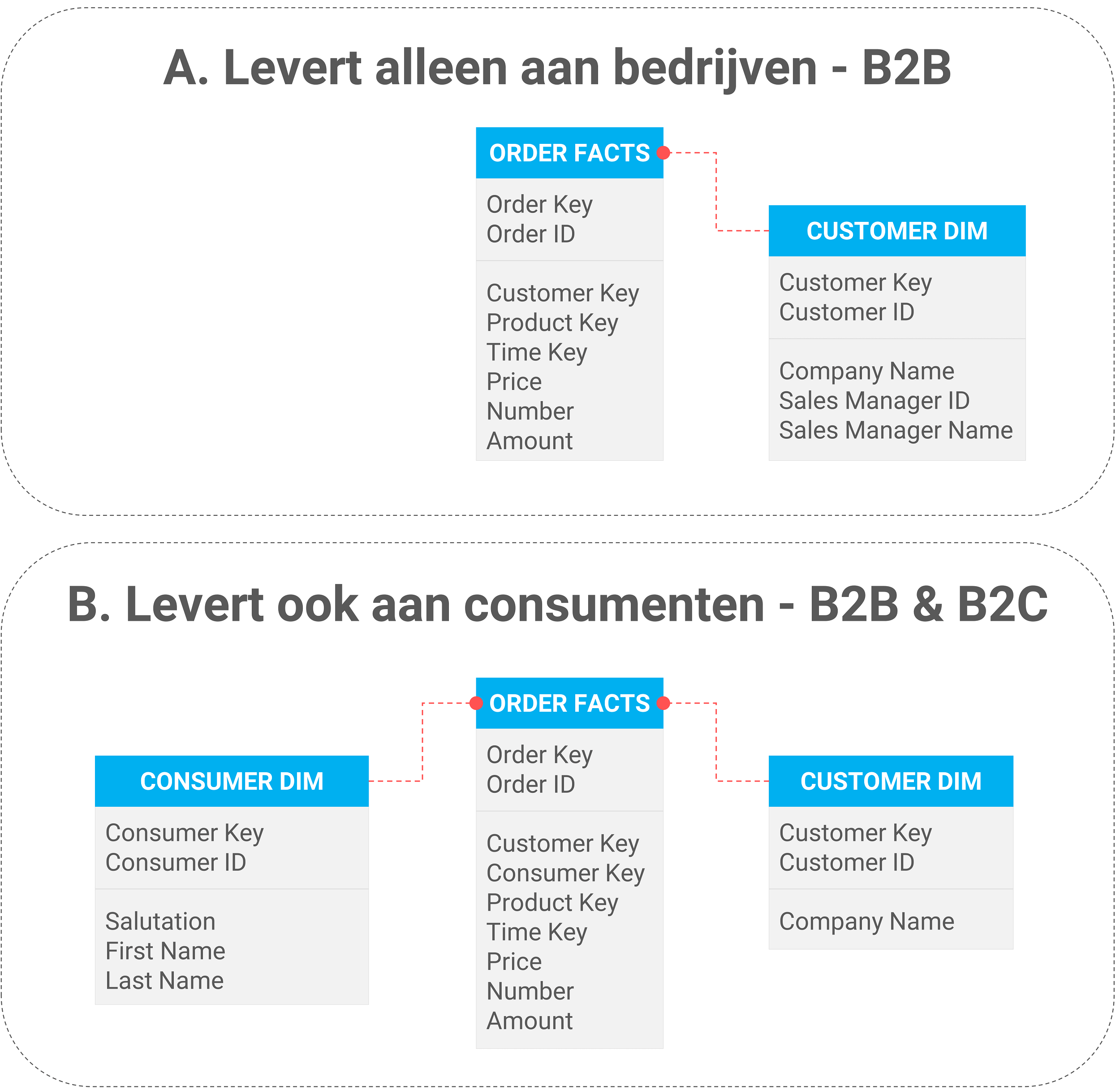
Figuur 5: datamodel van het datawarehouse voordat de wijziging in de bron optreedt (situatie A: alleen bedrijven) en het datamodel nadat de bron is gewijzigd (situatie B: ook consumenten kunnen nu bediend worden)
De Customer Key wordt gevuld wanneer er aan een bedrijf is geleverd (Consumer Key blijft leeg). De Consumer Key wordt gevuld wanneer er rechtstreeks aan de consument is geleverd (Customer Key blijft leeg). In het geval van tussenhandel worden zowel de Customer als de Consumer Key gevuld.
Andere modellering ook mogelijk
Overigens kun je de wijziging wat betreft sales managers en consumenten ook op een iets andere manier modelleren maar dat maakt voor de voorbeelden niet uit.
Datawarehouse Training, Governance & Data Vault In deze 3-daagse training Datawarehouse & Data Governance laat docent Dick Pouw MBA je kennis maken met het begrip datawarehouse (DWH), de beginselen van ETL en data integratie, het modelleren van een Data Vault (en starschema's), een centraal datawarehouse, data lakes en welke Data Governance jouw situatie vereist.
In deze 3-daagse training Datawarehouse & Data Governance laat docent Dick Pouw MBA je kennis maken met het begrip datawarehouse (DWH), de beginselen van ETL en data integratie, het modelleren van een Data Vault (en starschema's), een centraal datawarehouse, data lakes en welke Data Governance jouw situatie vereist.
Bronwijzigingen leiden altijd tot aanpassing van datamarts
Uit beide voorbeelden blijkt dat ook met een Data Vault het noodzakelijk is om het datamodel van het CDW/datamarts aan te passen wanneer de structuur van de bronnen wijzigt. Wat betekent dit voor de bestaande gegevens in het CDW/datamarts? Het CDW kan dan of compleet opnieuw worden opgebouwd uit de Data Vault (ETL/scriptaanpassingen zijn noodzakelijk). Of er dient een conversie-ETL geschreven te worden die bestaande data uit het CDW converteert naar de nieuwe structuur en inhoud.
Klopt het verhaal van herlaadbaarheid wel?
Het voordeel van herlaadbaarheid lijkt er dus niet te zijn. Immers in veel, maar niet alle, gevallen kan een conversie volstaan. Daarnaast kan een conversie de feitenrecords markeren van voor de conversie. Zodat je ook (achteraf) vast kan stellen wanneer de wijziging is ingegaan.
Situaties waarin een Data Vault wél meerwaarde heeft
- Vanuit het oogpunt van compliance en traceerbaarheid kan een Data Vault meerwaarde bieden. Immers, er vindt een nauwkeurige registratie plaats van het tijdstip dat een data-element uit welk bronsysteem de DWH-omgeving binnenkomt.
- Wanneer de structuur van bronsystemen frequent tot zeer frequent wijzigt, of de organisatie in een zeer dynamische omgeving opereert, kan een Data Vault meerwaarde bieden.
- Wanneer er veel verantwoordingsinformatie gegenereerd moet worden met vaste rapporten. Er kan dan worden volstaan met een zogenaamde Business Data Vault (die de rol van CDW heeft), zonder datamarts, waarin alleen juiste/correcte gegevens worden geladen. De BI tool haalt die rechtstreeks uit de Business Data Vault.

Ir. Rick van der Linden is een ervaren BI consultant, teamleider en associate partner bij Passionned Group. Hij is gespecialiseerd in data-analyse, datavisualisatie en Business Analytics. Neem contact op met Rick via LinkedIn.


























Reacties op dit artikel
Beste Rick,
Aardig stuk, en een prima inleiding op DV voor mensen die er nog niet veel van weten. Hier en daar heb ik nog wel wat aanmerkingen, met name op de opmerking “Pas je de Data Vault als CDW toe dan is er geen sprake van een volwassen DWH-architectuur.”
Een volwassen architectuur is naar mijn mening iets wat niet wordt bepaald door de vraag of je DV als CDW toepast. Eerder zie ik zaken als “loose coupling”, “resilience to change” en “privacy by design” als belangrijk in een DWH. Iedereen kent inmiddels de onderzoeken die aangeven dat onderhoudskosten 80% van de DWH-kosten uitmaken. Resilience to change, ondersteund door loose coupling, is daarmee zo’n beetje de belangrijkste overweging voor een DWH architect. Eentje die dus door het Data Vault model wordt geadresseerd.
Verder is een DV wat mij betreft geen component maar een architectuurlaag, met een eigen stel concerns: namelijk een robuuste opslag van temporeel consistente en onveranderlijke gegevens. Dat is vervelend voor clubs die maar wat aanklooien in de bronnen, en waarbij het DWH alle ellende mag oplossen. Dat gaat niet meer. En dan krijg je dus discussie over “de waarheid” versus “de feiten”. Dat is een discussie die een architect meteen bij de business neer moet leggen en niet in het DWH. Het is geen afvoerput.
Wat betreft “de belangrijkste nadelen van de Data Vault” kan ik deze als volgt adresseren:
“Meer werk: de Data Vault is complexer om te maken. Daarnaast heb je nu een extra component die je ook moet onderhouden.”
De “separation of concerns” die we toepassen bij een Data Vault vermindert de hoeveelheid werk per laag en maakt het werk per laag veel eenvoudiger. Weinig zaken zijn lastiger dan een groot dimensioneel model aanpassen waar alles van elkaar afhangt.
2) Meer transformaties: in de Data Vault normaliseer je entiteiten verder dan de bron. Nadien moet er ‘terug worden gewerkt’ naar een dimensioneel datamodel. Zie de afbeelding hierboven.
Dat geldt alleen als je een dimensioneel model als belangrijk beschouwt. Persoonlijk beschouw ik het als een query-optimalisatie model en een stukje caching. Bij een sterke database is deze nauwelijks nodig, en vaak als een stel views uit te voeren.
3) Meer kennis nodig: met de Data Vault komt er een derde modelleringstechniek bij. Medewerkers moeten die technieken stuk voor stuk beheersen.
Medewerkers moeten leren modelleren, en doorhebben dat een DV, of Anchor model, of Kimball model allemaal variaties op hetzelfde thema zijn. Dat vereist meer kennis. Mensen die dat niet kunnen voegen echter weinig toe aan een DWH team en lopen voornamelijk in de weg. Mijn ervaring is dat ik met 1 iemand, desnoods 2-3 mensen, een DWH kan bouwen. Meer mensen zijn zelden nodig. De plekken waar ik meer mensen zie rondhangen zijn plekken die flink kunnen afbouwen als ze betere mensen aannemen.
4) Geen integriteit: de gegevens zijn in de Data Vault niet integer en niet altijd juist.
Ze zijn integer met wat er is vastgelegd. En bij integratie op de hubs (het centrale thema van Data Vault!) zijn ze zeker ook onderling integer. Ze zijn daarmee dus ook juist ten opzichte van de bron. Maar ze zijn niet gemasseerd richting “de waarheid”. Een waarheid die er vaak ook niet is, maar met veel moeite wordt afgedwongen door bepaalde stakeholders. Dat is een politiek probleem, geen technisch issue. Door gebruik van business rule satellieten kan overigens prima een waarheid worden aangewezen. Maar die is dan wel volledig auditeerbaar en achteraf ook repareerbaar. Dat laatste is bij een CDW toch echt lastiger.
Kortom: ik denk dat een puur dimensioneel model leuk is voor DWH’s waarbij je rapporten bouwt voor één afnemer die “de waarheid” bepaalt, en als je weinig veranderingen tegenkomt en dus weinig bronnen ontsluit. Maar dat is in feite mijn definitie van een datamart. Zodra je een groot dataplatform opzet met veel stakeholders en bronnen, heb je echter een probleem met die methodiek. Data Vault kan een aantal problemen die dan ontstaan goed oplossen.
Hoi Rick, bedankt voor je duidelijke artikel.
Korte vraag. In Figuur 2. Heb je in de link table tussen Customer en Order Hub de inhoud volgens mij niet helemaal goed.
Hoort dit niet een Customer en Order kolom te zijn ipv 2 keer een customer kolom?
Waar zit anders de link naar de order Hub?
Misschien lees ik hem verkeerd?
Hi Michael,
Dank voor je oplettendheid, het is inderdaad zo dat in figuur 2 een foutje was geslopen. Dat is nu aangepast.
Groet,
Daan, namens Rick